

Оптимизация — одна из важнейших частей машинного обучения и искусственного интеллекта (AI). Основная цель обучения модели сводится к минимизации функции потерь (ошибки) или максимизации целевой функции, чтобы модель могла правильно предсказывать исходы.
Градиентный спуск — это ключевой алгоритм для нахождения оптимальных параметров моделей машинного обучения. В этом материале мы подробно рассмотрим понятия оптимизации, градиентного спуска и его вариаций, а также включим практические примеры.
1. Основные понятия оптимизации
1.1 Задача оптимизации
Оптимизация — это процесс нахождения экстремума (минимума или максимума) функции. В задачах машинного обучения нам обычно требуется минимизировать функцию потерь, которая измеряет разницу между предсказанными и реальными значениями. Функция потерь зависит от параметров модели, и задача состоит в том, чтобы найти такие значения этих параметров, которые минимизируют ошибку модели.
- Функция потерь (L(θ)): Функция, которая измеряет ошибку предсказаний модели. Например, для задачи регрессии часто используется среднеквадратичная ошибка (MSE):
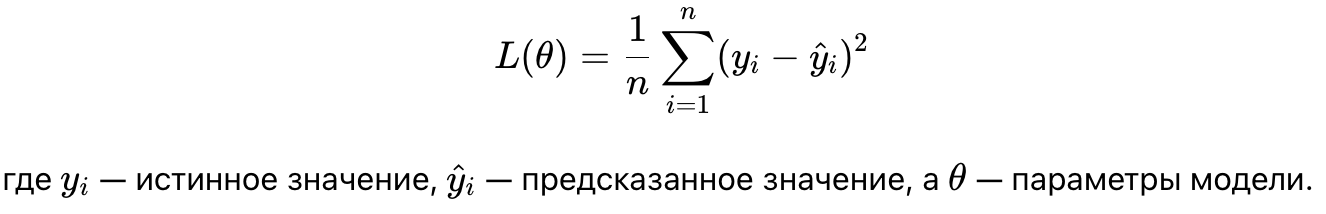
1.2 Виды оптимизации
- Минимизация: Наиболее распространенный тип задачи в машинном обучении. Мы хотим минимизировать функцию потерь, чтобы получить наилучшие предсказания.
- Максимизация: Иногда задачи сводятся к максимизации целевой функции, например, в байесовских моделях, где нужно максимизировать правдоподобие данных.
1.3 Выпуклые и невыпуклые функции
- Выпуклая функция: Это функция, у которой есть один глобальный минимум. Если функция выпуклая, то любой локальный минимум также является глобальным.
- Невыпуклая функция: Такие функции могут иметь несколько локальных минимумов и максимумов. Нейронные сети и сложные модели машинного обучения часто работают с невыпуклыми функциями.
Пример визуализации выпуклой и невыпуклой функции:
import numpy as np
import matplotlib.pyplot as plt
# Выпуклая функция (x^2) и невыпуклая функция (sin(x) + x^2)
x = np.linspace(-10, 10, 400)
y_convex = x ** 2
y_nonconvex = np.sin(x) + 0.1 * x ** 2
plt.plot(x, y_convex, label="Выпуклая функция")
plt.plot(x, y_nonconvex, label="Невыпуклая функция")
plt.legend()
plt.title("Выпуклая и невыпуклая функции")
plt.show()
2. Градиентный спуск
2.1 Принцип работы градиентного спуска
Градиентный спуск — это итеративный алгоритм оптимизации, который используется для минимизации функций. Его идея заключается в том, чтобы «двигаться» в направлении, противоположном градиенту функции потерь, поскольку градиент указывает на направление наибольшего увеличения функции.
- Градиент: Это вектор, составленный из частных производных функции по её параметрам. Он указывает направление максимального роста функции. Градиентный спуск корректирует параметры модели в направлении, противоположном градиенту, чтобы уменьшить ошибку.

Пример визуализации функции потерь и её градиента:
x = np.linspace(-10, 10, 100)
y = x ** 2
dy_dx = 2 * x
plt.plot(x, y, label='Функция потерь')
plt.quiver(x[::10], y[::10], -dy_dx[::10], np.zeros_like(dy_dx[::10]), scale=100, color='r', label='Градиент')
plt.legend()
plt.title("Градиентный спуск на примере функции y = x^2")
plt.show()
2.2 Алгоритм градиентного спуска
Инициализация параметров: Параметры модели (θ) инициализируются случайным образом.
Вычисление функции потерь: Для текущего набора параметров вычисляется значение функции потерь L(θ).
Вычисление градиента: Вычисляется градиент функции потерь по параметрам

Обновление параметров: Параметры обновляются по правилу
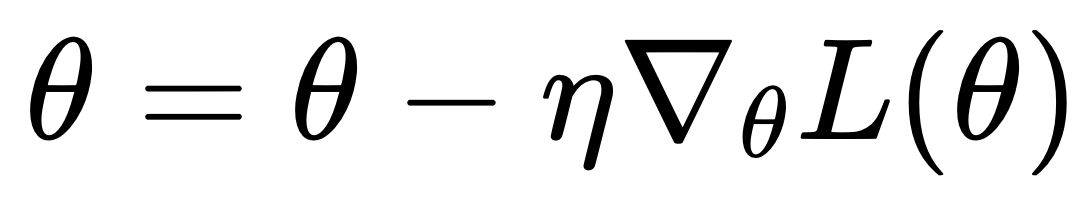
Проверка сходимости: Если изменения функции потерь становятся меньше заданного порога или достигается максимальное количество итераций, алгоритм останавливается.
3. Виды градиентного спуска
3.1 Полный (batch) градиентный спуск
- Описание: Полный градиентный спуск вычисляет градиент на всем наборе данных за одну итерацию. Это метод с высокой точностью, но при больших данных он может быть медленным и требовать значительных вычислительных ресурсов.
- Плюсы: Точный результат на каждом шаге.
- Минусы: Медленная обработка при больших данных, так как для каждого шага требуется обработать все данные.
3.2 Стохастический градиентный спуск (SGD)
- Описание: В стохастическом градиентном спуске градиент вычисляется на основе одного случайного примера данных. Это делает алгоритм быстрым, но он может быть менее точным из-за случайного характера каждого шага.
- Плюсы: Быстрая обработка, возможность работы с большими наборами данных.
- Минусы: Колебания и нестабильность в направлении сходимости.
3.3 Мини-пакетный градиентный спуск (Mini-batch SGD)
- Описание: Этот метод использует подмножества (мини-пакеты) данных для вычисления градиента. Это компромисс между точностью и скоростью.
- Плюсы: Быстрее полного градиентного спуска и более устойчив к шуму, чем стохастический.
- Минусы: Требует выбора размера мини-пакета (batch size).
Пример мини-пакетного градиентного спуска на Python:
import numpy as np
# Пример функции потерь
def loss_function(theta):
return theta ** 2
# Производная функции потерь
def gradient(theta):
return 2 * theta
# Градиентный спуск
def gradient_descent(initial_theta, learning_rate, iterations):
theta = initial_theta
for i in range(iterations):
grad = gradient(theta)
theta -= learning_rate * grad
print(f"Итерация {i+1}: theta = {theta}, loss = {loss_function(theta)}")
return theta
# Запуск алгоритма
gradient_descent(initial_theta=10, learning_rate=0.1, iterations=10)
4. Вариации градиентного спуска
4.1 Адаптивные методы обучения
В классическом градиентном спуске шаг обучения (η) остаётся постоянным на всех итерациях. Адаптивные методы изменяют шаг обучения на каждом шаге, чтобы ускорить сходимость.
- AdaGrad: Уменьшает шаг обучения для часто обновляемых параметров и увеличивает для редко обновляемых.
- RMSProp: Улучшает AdaGrad, корректируя проблему чрезмерного уменьшения шага обучения.
- Adam (Adaptive Moment Estimation): Один из наиболее популярных оптимизаторов, сочетающий преимущества AdaGrad и RMSProp, адаптирует шаг обучения на основе моментов градиентов.
import tensorflow as tf
# Пример использования оптимизатора Adam для обучения модели
model = tf.keras.Sequential([
tf.keras.layers.Dense(units=10, activation='relu'),
tf.keras.layers.Dense(units=1)
])
model.compile(optimizer='adam', loss='mean_squared_error')
4.2 Преимущества и недостатки методов
- Адаптивные методы (например, Adam) часто быстрее сходятся и требуют меньше ручной настройки шагов обучения, но в некоторых задачах могут приводить к колебаниям вокруг минимума.
- Классические методы (например, SGD) более стабильны, но требуют тщательной настройки параметров для достижения хорошей сходимости.
5. Проблемы и улучшения градиентного спуска
5.1 Локальные минимумы
Невыпуклые функции могут содержать несколько локальных минимумов, и градиентный спуск может «застревать» в них. Это особенно актуально для сложных моделей, таких как нейронные сети.
- Решение: Использование методов адаптивного обучения, таких как Adam, и использование стратегий изменения шага обучения, таких как learning rate scheduling.
5.2 Переобучение
Модели могут переобучаться, если слишком долго обучаются на тренировочных данных. Это приводит к тому, что модель теряет способность обобщать на новые данные.
- Решение: Применение регуляризации (например, L2-регуляризация), использование техники ранней остановки (early stopping) или снижение шага обучения на поздних этапах обучения.
Заключение
Оптимизация и градиентный спуск — это основа обучения моделей машинного обучения. Градиентный спуск и его вариации играют ключевую роль в минимизации ошибок моделей и нахождении оптимальных параметров. Понимание принципов работы этих методов и их практическое применение необходимо для успешного решения задач AI.
Рекомендации для самостоятельного изучения:
- Книга «Deep Learning» Иэна Гудфеллоу.
- Онлайн-курсы по оптимизации и градиентному спуску на Coursera и edX.
- Лекции по градиентному спуску и оптимизации от MIT OpenCourseWare.
Добавить комментарий