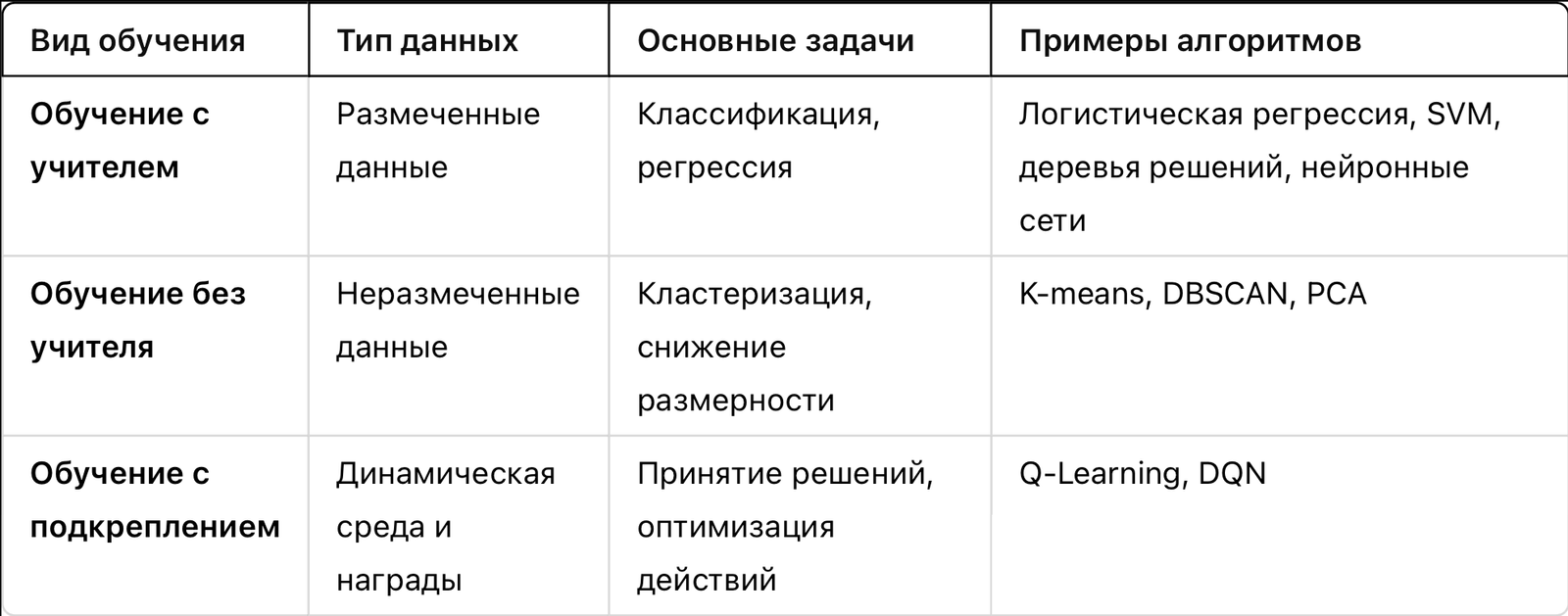
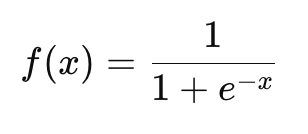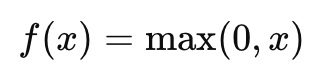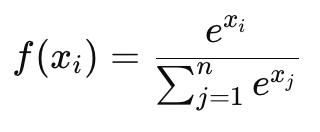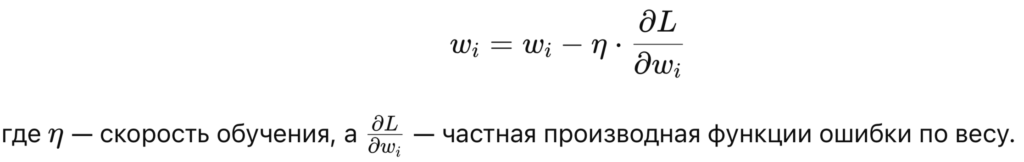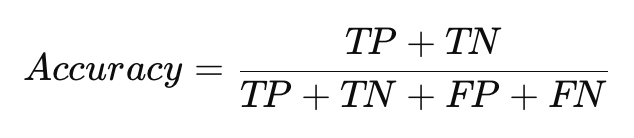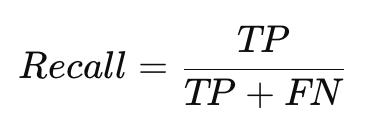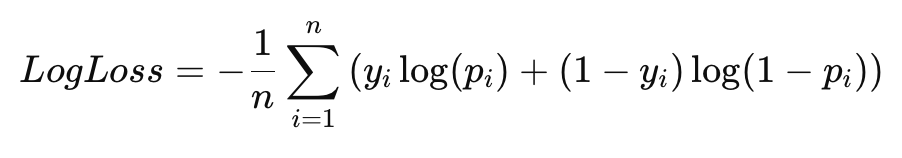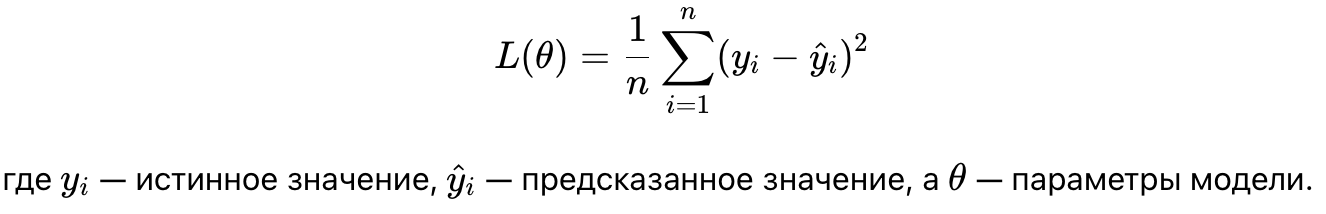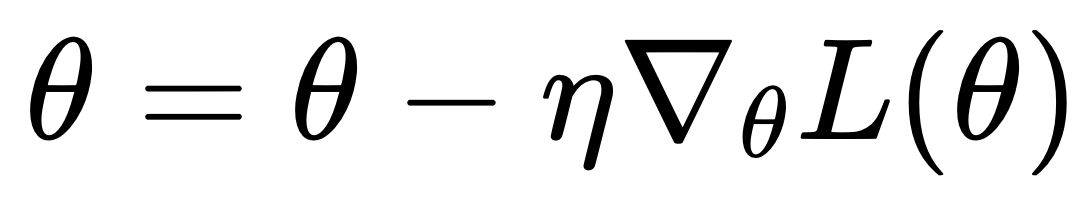Архитектура нейронной сети — это ее структура, которая определяет, как организованы слои и нейроны, как данные передаются и обрабатываются внутри сети. В зависимости от задачи используются различные архитектуры нейронных сетей. В этом материале мы рассмотрим три основных типа: полносвязные сети (FCN), сверточные нейронные сети (CNN) и рекуррентные нейронные сети (RNN). Эти архитектуры широко применяются в задачах, таких как классификация изображений, обработка текста и временных рядов.
Полносвязные сети (Fully Connected Networks, FCN)
Что такое полносвязные сети?
Полносвязные нейронные сети (FCN), также известные как многослойные перцептроны (MLP), являются базовой архитектурой нейронных сетей. В FCN каждый нейрон одного слоя связан с каждым нейроном следующего слоя. Полносвязные сети применяются в задачах, которые не зависят от пространственных или временных зависимостей, таких как табличные данные.
Структура полносвязной сети
Полносвязная сеть включает три типа слоев:
- Входной слой: Принимает данные, каждый нейрон этого слоя соответствует одному входному признаку.
- Скрытые слои: Эти слои обрабатывают входные данные, и число скрытых слоев и нейронов в них может варьироваться в зависимости от сложности задачи.
- Выходной слой: Производит итоговое предсказание. В задачах классификации для получения вероятности классов используется функция активации softmax, в задачах регрессии — линейная функция.
Применение полносвязных сетей
Полносвязные сети применяются в следующих задачах:
- Классификация табличных данных: Например, для предсказания класса клиента или его кредитного рейтинга.
- Регрессия: Прогнозирование числовых значений, таких как цена недвижимости или спрос на продукт.
- Простые задачи на классификацию изображений: FCN могут применяться для простых задач, хотя для изображений чаще используются CNN.
Пример полносвязной сети для бинарной классификации:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
# Модель полносвязной сети
model = Sequential([
Dense(64, input_dim=10, activation='relu'), # Скрытый слой с 64 нейронами
Dense(32, activation='relu'), # Второй скрытый слой с 32 нейронами
Dense(1, activation='sigmoid') # Выходной слой для бинарной классификации
])
# Компиляция модели
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Сверточные нейронные сети (Convolutional Neural Networks, CNN)
Что такое сверточные нейронные сети?
Сверточные нейронные сети (CNN) — это архитектура, предназначенная для работы с данными, имеющими пространственные зависимости, например, изображения и видео. CNN применяют свертку для извлечения признаков из данных, таких как контуры, текстуры, и объекты, что делает их очень эффективными для анализа изображений.
Структура сверточной сети
Основные компоненты CNN:
Сверточный слой (Convolutional Layer):
Этот слой применяет свертку с использованием фильтров (kernels), которые извлекают признаки из изображений. Свертка позволяет выделять локальные признаки, такие как границы и текстуры.
Слой активации:
Обычно используется функция активации ReLU для придания модели нелинейности.
Пуллинг (Pooling):
Слой пуллинга уменьшает размер карты признаков, сохраняя важные данные. Наиболее часто используется max pooling, который выбирает максимальное значение из каждой области.
Полносвязный слой:
На финальном этапе данные передаются в полносвязный слой для предсказания класса.
Применение сверточных сетей
Сверточные нейронные сети широко применяются в задачах:
- Компьютерное зрение: Распознавание объектов, классификация и сегментация изображений.
- Обработка видео: Выделение признаков в последовательностях изображений.
- Распознавание изображений: Распознавание лиц, транспортных средств, товаров в электронной коммерции.
Пример CNN для классификации изображений:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Модель сверточной сети
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)), # Сверточный слой
MaxPooling2D(pool_size=(2, 2)), # Пуллинг слой
Flatten(), # Преобразование в одномерный массив
Dense(128, activation='relu'), # Полносвязный слой
Dense(1, activation='sigmoid') # Выходной слой для бинарной классификации
])
# Компиляция модели
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Рекуррентные нейронные сети (Recurrent Neural Networks, RNN)
Что такое рекуррентные нейронные сети?
Рекуррентные нейронные сети (RNN) предназначены для работы с последовательными данными, такими как текст, временные ряды или аудио. В отличие от стандартных нейронных сетей, RNN могут хранить информацию о предыдущих шагах последовательности через скрытые состояния, что позволяет учитывать временные зависимости.
Структура рекуррентной сети
Основные элементы RNN:
- Скрытые состояния: На каждом шаге сеть обновляет свои скрытые состояния, что позволяет учитывать контекст предыдущих шагов при обработке текущего шага.
- Ячейки LSTM и GRU: Обычные RNN страдают от проблемы исчезающего градиента, что затрудняет обучение на длинных последовательностях. LSTM (Long Short-Term Memory) и GRU (Gated Recurrent Unit) решают эту проблему, эффективно запоминая важную информацию.
Применение рекуррентных сетей
RNN применяются в следующих областях:
- Обработка естественного языка (NLP): Машинный перевод, генерация текста, анализ тональности.
- Прогнозирование временных рядов: Финансовое прогнозирование, предсказание спроса, анализ временных данных.
- Распознавание речи: Преобразование речи в текст и наоборот.
Пример RNN для обработки последовательных данных:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import SimpleRNN, Dense
# Модель рекуррентной сети
model = Sequential([
SimpleRNN(50, input_shape=(10, 1), activation='tanh'), # Рекуррентный слой
Dense(1, activation='linear') # Полносвязный слой для регрессии
])
# Компиляция модели
model.compile(optimizer='adam', loss='mean_squared_error')
LSTM и GRU
LSTM и GRU являются улучшенными версиями RNN, разработанными для лучшего запоминания долгосрочных зависимостей в последовательностях. Они используют специальные механизмы «запоминания» и «забывания», что делает их более устойчивыми к проблемам исчезающего градиента.
Пример использования LSTM:
from tensorflow.keras.layers import LSTM
# Модель с использованием LSTM
model = Sequential([
LSTM(50, input_shape=(10, 1)), # LSTM слой
Dense(1, activation='linear') # Выходной слой для регрессии
])
Регуляризация и предотвращение переобучения
Регуляризация помогает предотвратить переобучение, когда модель слишком хорошо подгоняется под тренировочные данные и плохо обобщает на новые данные.
Dropout
Dropout — это техника регуляризации, при которой во время обучения случайным образом «выключаются» некоторые нейроны. Это помогает избежать сильной зависимости модели от определенных нейронов и улучшает её способность к обобщению.
Пример использования Dropout:
from tensorflow.keras.layers import Dropout # Добавление слоя Dropout model.add(Dropout(0.5)) # 50% нейронов случайно выключаются
Batch Normalization
Batch Normalization нормализует входные данные для каждого слоя, что помогает ускорить обучение и сделать его более стабильным. Этот метод особенно полезен для глубоких сетей.
Пример использования Batch Normalization:
from tensorflow.keras.layers import BatchNormalization # Добавление слоя Batch Normalization model.add(BatchNormalization())
Применение архитектур нейронных сетей
Различные архитектуры нейронных сетей используются в различных задачах:
- Полносвязные сети (FCN): Подходят для задач классификации и регрессии на табличных данных.
- Сверточные сети (CNN): Используются для задач обработки изображений и видео.
- Рекуррентные сети (RNN): Эффективны при работе с последовательностями данных, такими как текст, временные ряды и аудио.
Заключение
Каждая архитектура нейронной сети — полносвязные сети, сверточные сети и рекуррентные сети — имеет свои уникальные особенности и подходит для различных типов задач. Полносвязные сети применяются для работы с табличными данными, сверточные — для анализа изображений, а рекуррентные — для последовательных данных. Понимание различий между архитектурами и их особенностей помогает выбрать правильный подход для решения конкретной задачи.
Рекомендации для самостоятельного изучения:
- Книга «Deep Learning» от Ian Goodfellow.
- Онлайн-курсы по нейронным сетям на Coursera (DeepLearning).
- Практические проекты на Kaggle.