

Оценка качества моделей машинного обучения — важный шаг в процессе построения и оптимизации моделей. Правильный выбор метрики позволяет объективно оценить, насколько эффективно модель решает задачу. В зависимости от специфики задачи и данных могут использоваться различные метрики, такие как точность, полнота, F-мера, а также ROC-AUC и логарифмическая функция потерь (Log-Loss). В этом материале мы рассмотрим основные метрики, используемые для задач классификации, их математические основы, примеры использования, а также как интерпретировать результаты.
Матрица ошибок (Confusion Matrix)
Матрица ошибок — это таблица, которая показывает, как модель классифицирует объекты на основе их истинных и предсказанных классов. Она разбивает предсказания на четыре категории:
- True Positive (TP): Модель правильно предсказала положительный класс.
- False Positive (FP): Модель ошибочно предсказала положительный класс, хотя на самом деле класс отрицательный.
- True Negative (TN): Модель правильно предсказала отрицательный класс.
- False Negative (FN): Модель ошибочно предсказала отрицательный класс, хотя на самом деле класс положительный.
Визуализация матрицы ошибок:
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.metrics import confusion_matrix
# Пример истинных значений и предсказанных значений
y_true = [0, 1, 1, 0, 1, 0, 1]
y_pred = [0, 1, 0, 0, 1, 1, 1]
# Создание и визуализация матрицы ошибок
cm = confusion_matrix(y_true, y_pred)
sns.heatmap(cm, annot=True, fmt='d', cmap='Blues')
plt.title('Матрица ошибок')
plt.xlabel('Предсказано')
plt.ylabel('Истинное')
plt.show()
Основные метрики оценки
Точность (Accuracy) — это доля правильно предсказанных примеров (как положительных, так и отрицательных) среди всех примеров.
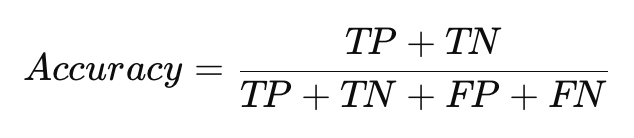
- Преимущества: Легко интерпретируется и работает хорошо на сбалансированных данных.
- Недостатки: На несбалансированных данных точность может вводить в заблуждение, если большинство примеров относятся к одному классу.
Пример расчета точности:
from sklearn.metrics import accuracy_score
# Пример истинных и предсказанных значений
y_true = [0, 1, 1, 0, 1, 0, 1]
y_pred = [0, 1, 0, 0, 1, 1, 1]
# Вычисление точности
accuracy = accuracy_score(y_true, y_pred)
print(f"Точность: {accuracy:.2f}")
Полнота (Recall)
Полнота (Recall), также известная как чувствительность, показывает, как хорошо модель распознает все истинные положительные примеры.
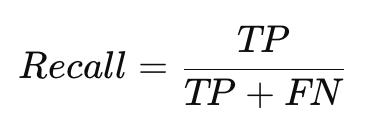
- Преимущества: Важна в ситуациях, где важнее не пропустить положительные примеры, например, в медицинской диагностике.
- Недостатки: Если модель предсказывает много ложноположительных результатов, она может иметь высокую полноту, но низкую точность.
Пример расчета полноты:
from sklearn.metrics import recall_score
# Вычисление полноты
recall = recall_score(y_true, y_pred)
print(f"Полнота: {recall:.2f}")
Точность предсказания (Precision)
Точность предсказания (Precision) измеряет, насколько точны положительные предсказания модели.

- Преимущества: Полезна в задачах, где важно минимизировать количество ложноположительных предсказаний, например, в спам-фильтрах.
- Недостатки: Может давать слишком высокую оценку, если модель редко предсказывает положительные классы.
Пример расчета точности предсказания:
from sklearn.metrics import precision_score
# Вычисление точности предсказания
precision = precision_score(y_true, y_pred)
print(f"Точность предсказания: {precision:.2f}")
F-мера (F1-score)
F-мера (F1-score) — это среднее гармоническое между точностью предсказания и полнотой. Она полезна в задачах с несбалансированными данными, так как учитывает оба показателя.

- Преимущества: Комбинирует точность предсказания и полноту, что делает её полезной для оценки моделей на несбалансированных данных.
- Недостатки: Может быть сложно интерпретировать отдельно без контекста.
Пример расчета F1-меры:
from sklearn.metrics import f1_score
# Вычисление F1-меры
f1 = f1_score(y_true, y_pred)
print(f"F1-мера: {f1:.2f}")
Дополнительные метрики
ROC-кривая и AUC (Area Under Curve)
ROC-кривая (Receiver Operating Characteristic) — это график, который показывает соотношение между полнотой (Recall) и ложноположительными срабатываниями (False Positive Rate) при различных порогах классификации.
- AUC (Area Under Curve) — площадь под ROC-кривой. Чем ближе AUC к 1, тем лучше модель разделяет классы. AUC = 0.5 означает, что модель предсказывает случайно.
Пример построения ROC-кривой:
from sklearn.metrics import roc_curve, auc
import matplotlib.pyplot as plt
# Пример истинных значений и предсказанных вероятностей
y_true = [0, 1, 1, 0, 1, 0, 1]
y_scores = [0.2, 0.8, 0.6, 0.4, 0.9, 0.3, 0.7]
# Построение ROC-кривой
fpr, tpr, thresholds = roc_curve(y_true, y_scores)
roc_auc = auc(fpr, tpr)
# Визуализация ROC-кривой
plt.figure()
plt.plot(fpr, tpr, color='darkorange', lw=2, label=f'ROC-кривая (AUC = {roc_auc:.2f})')
plt.plot([0, 1], [0, 1], color='navy', lw=2, linestyle='--')
plt.xlabel('False Positive Rate')
plt.ylabel('Recall')
plt.title('ROC-кривая')
plt.legend(loc='lower right')
plt.show()
Логарифмическая функция потерь (Log-Loss)
Log-Loss — это метрика, которая измеряет, насколько хорошо предсказанные вероятности соответствуют реальным классам. Она полезна для задач, где важны вероятностные предсказания.
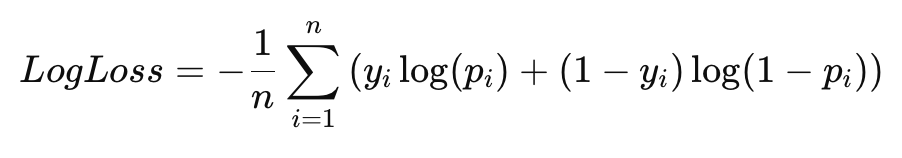
Пример расчета Log-Loss:
from sklearn.metrics import log_loss
# Пример истинных значений и предсказанных вероятностей
y_true = [0, 1, 1, 0, 1, 0, 1]
y_probs = [0.1, 0.9, 0.8, 0.2, 0.85, 0.3, 0.75]
# Вычисление Log-Loss
log_loss_value = log_loss(y_true, y_probs)
print(f"Log-Loss: {log_loss_value:.2f}")
Метрики для многоклассовой классификации
Для задач многоклассовой классификации метрики, такие как точность, полнота и F1-мера, могут быть адаптированы для нескольких классов. Используются два подхода:
- Micro-averaging: Суммирует TP, FP, FN по всем классам и вычисляет метрику.
- Macro-averaging: Вычисляет метрику для каждого класса и усредняет их.
Пример расчета F1-меры для многоклассовой классификации:
from sklearn.metrics import f1_score
# Пример многоклассовых данных
y_true = [0, 1, 2, 0, 1, 2]
y_pred = [0, 2, 1, 0, 0, 1]
# Вычисление F1-меры для каждого класса
f1_macro = f1_score(y_true, y_pred, average='macro')
f1_micro = f1_score(y_true, y_pred, average='micro')
print(f"F1-мера (Macro): {f1_macro:.2f}")
print(f"F1-мера (Micro): {f1_micro:.2f}")
Как выбрать правильную метрику?
- Точность (Accuracy): Используйте на сбалансированных данных, где классы примерно одинаковы по частоте.
- Полнота (Recall): Важна в задачах, где пропуск положительных примеров может иметь серьезные последствия (например, медицина).
- Точность предсказания (Precision): Полезна, когда важно минимизировать ложные срабатывания (например, спам-фильтры).
- F1-мера: Полезна на несбалансированных данных, когда требуется баланс между полнотой и точностью предсказаний.
- ROC-AUC: Важна, когда требуется оценить способность модели ранжировать примеры по вероятности принадлежности к классу.
Заключение
Методы оценки качества моделей играют ключевую роль в процессе построения эффективных решений на основе машинного обучения. Точность, полнота, F-мера и ROC-AUC являются основными метриками, которые помогают объективно оценить эффективность модели. Понимание этих метрик позволяет выбрать оптимальную модель для конкретной задачи и улучшить ее производительность.
Рекомендации для самостоятельного изучения:
- Книга «Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow» от Aurélien Géron.
- Онлайн-курсы по машинному обучению на Coursera и edX.
- Лекции по машинному обучению от MIT OpenCourseWare.
Добавить комментарий