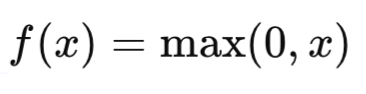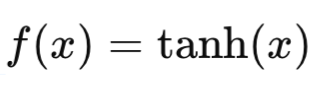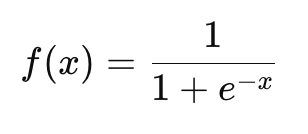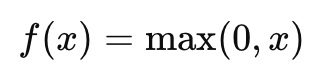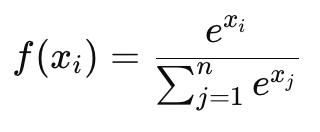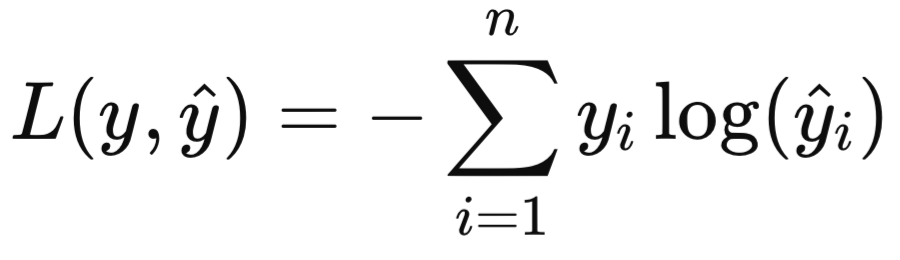Компьютерное зрение — это область искусственного интеллекта, которая фокусируется на том, как компьютеры могут «видеть» и интерпретировать визуальные данные, такие как изображения и видео. Цель компьютерного зрения — научить машины анализировать визуальную информацию так же эффективно, как это делает человеческий мозг. В последние годы технологии компьютерного зрения нашли применение во множестве отраслей, таких как медицина, автомобильная промышленность, системы безопасности, производство и развлечения.
Основные задачи компьютерного зрения
Распознавание объектов (Object Detection)
Распознавание объектов — это задача, связанная с нахождением и классификацией объектов на изображении или видео. Важные аспекты задачи:
- Локализация объекта: Определение границ или координат объекта на изображении.
- Классификация объекта: Отнесение объекта к определённой категории (например, автомобиль, человек, животное).
Популярные алгоритмы распознавания объектов:
- YOLO (You Only Look Once): Быстрая модель для распознавания объектов в реальном времени, которая выполняет локализацию и классификацию одновременно.
- Faster R-CNN: Модель, которая сначала генерирует предложения регионов, а затем классифицирует их. Она обеспечивает более точное распознавание, но работает медленнее, чем YOLO.
Пример работы с YOLO для распознавания объектов:
import cv2
# Загрузка изображения
image = cv2.imread('image.jpg')
# Загрузка предобученной модели YOLO
# Пример загрузки YOLO модели для детекции объектов
# Используйте библиотеку cv2 dnn и предобученные веса модели
Сегментация изображений (Image Segmentation)
Сегментация изображений — это процесс разделения изображения на отдельные регионы, соответствующие различным объектам или их частям. Важные виды сегментации:
- Семантическая сегментация: Все пиксели, принадлежащие к одному объекту, помечаются одинаково. Например, все пиксели, относящиеся к автомобилю, помечаются одинаковым цветом.
- Инстанс-сегментация: Разделяет разные экземпляры одного объекта (например, несколько автомобилей на изображении).
Популярные алгоритмы для сегментации изображений:
- U-Net: Архитектура, специально разработанная для сегментации медицинских изображений, которая нашла применение в других областях.
- Mask R-CNN: Это расширение Faster R-CNN, которое позволяет не только обнаруживать объекты, но и создавать их маски для сегментации.
Классификация изображений (Image Classification)
Классификация изображений — это задача, при которой изображение целиком относится к одному из заданных классов. Например, задача может заключаться в том, чтобы классифицировать изображение как «собака», «кошка» или «машина». Это одна из самых популярных задач в компьютерном зрении.
Популярные архитектуры для классификации:
- ResNet: Глубокая архитектура с остаточными блоками, которая решает проблему исчезающего градиента и позволяет создавать более глубокие модели.
- VGG: Модель с последовательными сверточными слоями, которая широко используется для классификации изображений.
Пример использования предобученной модели ResNet для классификации изображений:
from tensorflow.keras.applications import ResNet50 # Загрузка предобученной модели ResNet50 model = ResNet50(weights='imagenet') # Предсказание класса изображения predictions = model.predict(image)
2.4 Анализ видео (Video Analysis)
Анализ видео включает задачи отслеживания объектов и понимания динамики событий в видеопотоке. Примером может быть отслеживание движения автомобилей или людей, анализ поведения или обнаружение аномалий.
Популярные методы для анализа видео:
- Оптический поток: Метод для определения движения объектов между кадрами.
- DeepSORT: Модель для отслеживания нескольких объектов на видео в реальном времени.
Основные методы и архитектуры в компьютерном зрении
Сверточные нейронные сети (Convolutional Neural Networks, CNN)
Сверточные нейронные сети (CNN) — это основная архитектура, используемая для решения задач компьютерного зрения. В CNN используются фильтры для свертки, что позволяет выделять важные пространственные признаки на изображениях.
Основные компоненты CNN:
- Сверточные слои: Выполняют свертку изображения с помощью фильтров для извлечения признаков, таких как контуры, текстуры и формы.
- Пуллинговые слои: Уменьшают размер изображения, сохраняя важные признаки.
- Полносвязные слои: Завершают архитектуру и выполняют классификацию изображений.
Пример структуры сверточной сети:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense
# Создание CNN
model = Sequential([
Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3)), # Сверточный слой
MaxPooling2D(pool_size=(2, 2)), # Пуллинговый слой
Flatten(), # Преобразование в вектор
Dense(128, activation='relu'), # Полносвязный слой
Dense(10, activation='softmax') # Выходной слой для классификации
])
Современные архитектуры глубокого обучения
Популярные архитектуры для задач компьютерного зрения:
- ResNet: Использует остаточные блоки для решения проблемы исчезающего градиента и позволяет эффективно обучать очень глубокие сети.
- Inception: Включает параллельные сверточные фильтры разных размеров для извлечения различных признаков.
- MobileNet: Легковесная модель, оптимизированная для мобильных устройств и встраиваемых систем.
Применение предобученных моделей и transfer learning
Предобученные модели, такие как ResNet, VGG и EfficientNet, широко используются для ускорения разработки. Они уже обучены на больших наборах данных (например, ImageNet) и могут быть дообучены на конкретных задачах с использованием техники transfer learning.
Пример дообучения предобученной модели ResNet:
from tensorflow.keras.applications import ResNet50 from tensorflow.keras.layers import Dense, Flatten from tensorflow.keras.models import Model # Загрузка предобученной модели base_model = ResNet50(weights='imagenet', include_top=False, input_shape=(224, 224, 3)) # Добавление новых слоев x = base_model.output x = Flatten()(x) x = Dense(1024, activation='relu')(x) predictions = Dense(10, activation='softmax')(x) # Создание новой модели model = Model(inputs=base_model.input, outputs=predictions) # Компиляция и дообучение model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy']) model.fit(X_train, y_train, epochs=5)
Современные подходы к улучшению качества изображений
Generative Adversarial Networks (GAN)
Генеративные состязательные сети (GAN) — это подход, который позволяет создавать новые изображения, улучшать качество существующих или даже создавать стилизованные изображения. GAN состоят из двух нейросетей — генератора и дискриминатора, которые «соревнуются» друг с другом. Генератор пытается создать реалистичные изображения, а дискриминатор — отличить их от реальных изображений.
Применение GAN:
- Генерация реалистичных изображений (например, лиц).
- Улучшение разрешения изображений (суперразрешение).
Применение компьютерного зрения
Компьютерное зрение активно используется в различных отраслях:
- Медицина: Анализ медицинских изображений для диагностики заболеваний.
- Автономные транспортные средства: Распознавание объектов на дороге, включая автомобили, пешеходов, знаки.
- Электронная коммерция: Автоматическая классификация товаров по изображениям, визуальные поисковые системы.
- Безопасность: Системы видеонаблюдения и распознавания лиц.
- Развлечения и игры: Генерация персонажей и объектов для видеоигр и кино.
Заключение
Компьютерное зрение — это ключевая область ИИ, которая позволяет компьютерам «видеть» и интерпретировать визуальные данные. На основе сверточных нейронных сетей и современных архитектур глубокого обучения, таких как ResNet и YOLO, машины могут выполнять задачи распознавания, сегментации и анализа изображений и видео с высокой точностью. В ближайшие годы применение компьютерного зрения будет только расширяться, открывая новые возможности для автоматизации и улучшения существующих систем.
Рекомендации для самостоятельного изучения:
- Книга «Deep Learning» от Ian Goodfellow.
- Курсы по компьютерному зрению на Coursera (DeepLearning.ai).
- Практические задачи на платформе Kaggle.