

Процесс обучения нейронной сети — это ключевой элемент глубокого обучения, который позволяет сети адаптировать свои веса и параметры, чтобы точно предсказывать результаты на основе данных. В этом материале мы подробно разберем два основных компонента обучения нейронных сетей: обратное распространение ошибки и функции активации. Также рассмотрим методы оптимизации, регуляризацию и основные проблемы, возникающие при обучении глубоких сетей.
Обратное распространение ошибки (Backpropagation)
Что такое обратное распространение ошибки?
Обратное распространение ошибки — это алгоритм, который используется для настройки весов в нейронной сети с целью минимизации ошибки (или функции потерь). Этот метод позволяет модели корректировать свои веса в зависимости от ошибки, полученной на этапе предсказания, и на каждом шаге улучшать точность предсказаний.
Процесс состоит из нескольких этапов:
- Прямое распространение (Forward Propagation): Входные данные проходят через сеть, и каждый нейрон производит выход, который затем передается на следующий слой.
- Вычисление функции потерь: На выходном слое вычисляется ошибка между предсказанием модели и истинными значениями с помощью функции потерь.
- Обратное распространение ошибки: Ошибка распространяется от выходного слоя к предыдущим слоям, и рассчитываются градиенты, которые показывают, насколько сильно каждый вес повлиял на ошибку.
- Обновление весов: Используя градиенты, веса корректируются с использованием метода оптимизации, например, градиентного спуска, с целью минимизации ошибки.
Функции ошибки
Функции ошибки измеряют, насколько предсказание модели отклоняется от истинных значений. Наиболее часто используемые функции ошибки:
MSE (Mean Squared Error) для задач регрессии:
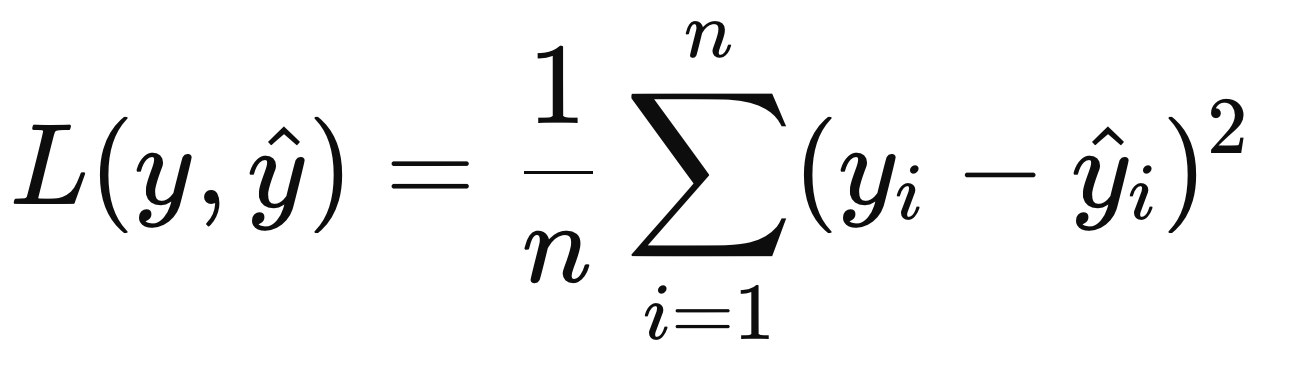
Cross-Entropy (Перекрестная энтропия) для задач классификации:

Градиентный спуск
Градиентный спуск — это метод оптимизации, используемый для минимизации функции потерь. Он корректирует веса нейронов, двигаясь в направлении, которое минимизирует ошибку. Веса обновляются на основе вычисленных градиентов.
Формула обновления весов:
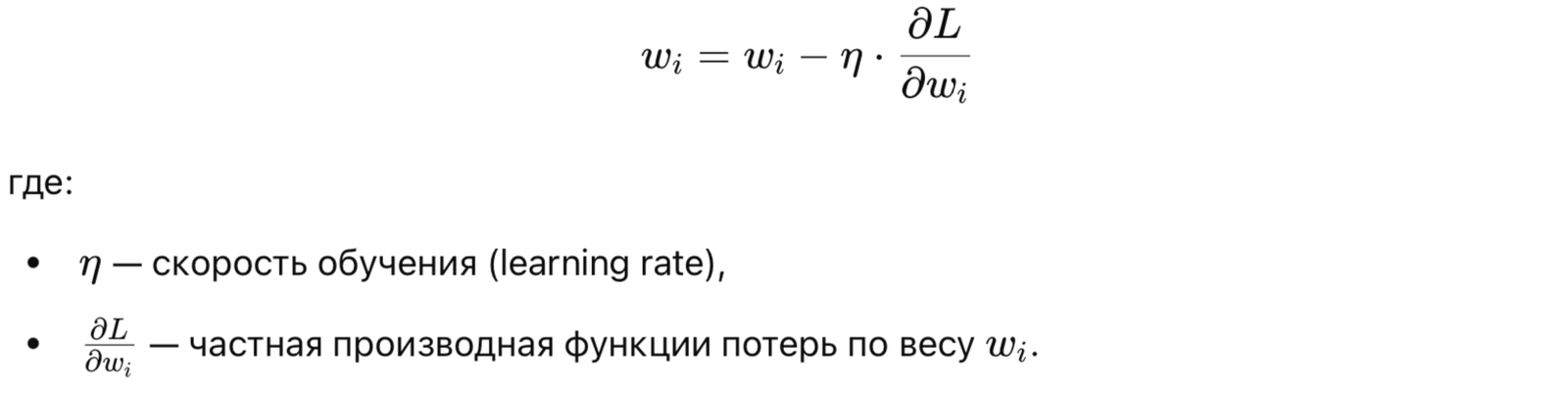
Варианты градиентного спуска
Существует несколько модификаций градиентного спуска, каждая из которых помогает ускорить и стабилизировать процесс обучения:
- Сточастический градиентный спуск (SGD): Обновляет веса после обработки каждого примера в тренировочном наборе данных. Это ускоряет обучение, но может вызывать колебания функции потерь.
- Mini-batch SGD: Данные разбиваются на небольшие пакеты (batch), и веса обновляются после обработки каждого пакета. Этот метод сохраняет баланс между скоростью обучения и стабильностью.
- Adam (Adaptive Moment Estimation): Один из наиболее популярных оптимизаторов, который автоматически корректирует скорость обучения для каждого параметра на основе первых и вторых моментов градиентов. Adam сочетает преимущества SGD и адаптивных методов, таких как RMSProp.
Пример использования Adam в Keras:
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
Проблемы обучения
- Исчезающий градиент: В глубоких сетях градиенты могут становиться очень маленькими на слоях, близких к началу, что затрудняет обновление весов. Это приводит к медленному или почти отсутствующему обучению. Решения включают использование ReLU в качестве функции активации и инициализацию весов с помощью He инициализации.
- Взрывающийся градиент: В противоположность исчезающему градиенту, градиенты могут становиться слишком большими, что приводит к нестабильности обучения. Решения включают нормализацию градиентов или Clip Gradient для ограничения их максимального значения.
Функции активации
Что такое функции активации?
Функция активации определяет, будет ли нейрон активен, т.е. передаст ли он сигнал дальше. Важность функций активации заключается в том, что они добавляют нелинейность в модель, позволяя нейронной сети решать более сложные задачи, чем линейные модели.
Основные функции активации
Sigmoid — для задач бинарной классификации.
Преобразует входное значение в диапазон от 0 до 1. Обычно используется в задачах бинарной классификации.
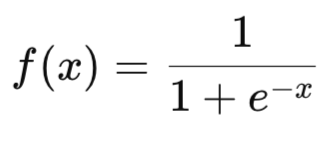
Пример:
from tensorflow.keras.layers import Dense model.add(Dense(1, activation='sigmoid')) # Для бинарной классификации
ReLU (Rectified Linear Unit) — для скрытых слоев, особенно в глубоких сетях, так как она ускоряет процесс обучения.
Самая популярная функция активации, возвращающая 0 для отрицательных значений и само значение для положительных. ReLU широко используется в скрытых слоях глубоких сетей.
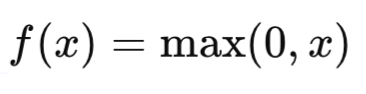
Пример:
model.add(Dense(64, activation='relu')) # Скрытый слой с ReLU активацией
Tanh — используется в рекуррентных сетях, когда требуется сбалансировать данные вокруг нуля.
Преобразует значения в диапазон от -1 до 1, что делает её полезной для обработки данных, содержащих как положительные, так и отрицательные значения. Tanh часто используется в RNN.
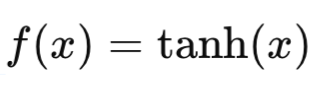
Softmax — для многоклассовой классификации, так как она преобразует выходы в вероятности классов.
Преобразует набор выходных значений в вероятности, которые суммируются до 1. Используется в выходных слоях для многоклассовой классификации.

model.add(Dense(3, activation='softmax')) # Для многоклассовой классификации
Регуляризация в нейронных сетях
Dropout
Dropout — это метод регуляризации, при котором случайным образом «выключаются» некоторые нейроны во время обучения. Это помогает предотвратить переобучение (overfitting), делая сеть менее зависимой от отдельных нейронов.
Пример использования Dropout:
from tensorflow.keras.layers import Dropout model.add(Dropout(0.5)) # 50% нейронов случайно выключаются
L2-регуляризация (Weight Decay)
L2-регуляризация добавляет штраф за слишком большие веса в сети, тем самым уменьшая склонность модели к переобучению. Это помогает сделать модель более устойчивой.
Пример использования L2-регуляризации:
from tensorflow.keras.regularizers import l2 model.add(Dense(64, activation='relu', kernel_regularizer=l2(0.01)))
Batch Normalization
Batch Normalization нормализует входные данные для каждого слоя, что помогает ускорить обучение и делает его более стабильным. Этот метод особенно полезен в глубоких сетях.
Пример использования Batch Normalization:
from tensorflow.keras.layers import BatchNormalization model.add(BatchNormalization())
Полный процесс обучения нейронной сети
Давайте рассмотрим полный процесс обучения нейронной сети с использованием функций активации, методов регуляризации и оптимизаторов:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, BatchNormalization
# Создание модели
model = Sequential([
Dense(128, input_dim=20, activation='relu'), # Скрытый слой с ReLU
BatchNormalization(), # Нормализация данных
Dropout(0.5), # Dropout для регуляризации
Dense(64, activation='relu'), # Второй скрытый слой с ReLU
Dense(1, activation='sigmoid') # Выходной слой для бинарной классификации
])
# Компиляция модели с оптимизатором Adam
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Обучение модели
history = model.fit(X_train, y_train, epochs=20, batch_size=32, validation_split=0.2)
# Оценка модели
loss, accuracy = model.evaluate(X_test, y_test)
print(f"Точность на тестовых данных: {accuracy:.4f}")
Визуализация процесса обучения
Также полезно визуализировать процесс обучения, чтобы видеть, как изменяется ошибка на тренировочной и валидационной выборках:
import matplotlib.pyplot as plt
# График потерь на обучающей и валидационной выборке
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('График обучения')
plt.xlabel('Эпохи')
plt.ylabel('Потери')
plt.legend()
plt.show()
Заключение
Процесс обучения нейронных сетей включает обратное распространение ошибки, применение функций активации, использование методов регуляризации и оптимизации. Обратное распространение и градиентный спуск позволяют сети корректировать свои веса и минимизировать ошибку, а функции активации добавляют нелинейность, необходимую для решения сложных задач. Регуляризация, такая как Dropout и L2-регуляризация, предотвращает переобучение и делает модель более стабильной.
Рекомендации для самостоятельного изучения:
- Книга «Deep Learning» от Ian Goodfellow.
- Онлайн-курсы по нейронным сетям на Coursera (DeepLearning.ai).
- Практические задачи по работе с нейронными сетями на Kaggle.
Добавить комментарий