

Сверточные нейронные сети (Convolutional Neural Networks, CNN) — это архитектуры глубокого обучения, разработанные для эффективной работы с изображениями и другими типами данных с пространственной структурой. Они моделируют работу человеческой зрительной системы и используют механизмы сверток для выделения важных признаков изображений (краёв, текстур, объектов). CNN нашли широкое применение в задачах классификации изображений, распознавания объектов, сегментации и анализа видеопотоков.
В этом материале мы подробно рассмотрим основные компоненты CNN, архитектуру, продвинутые модели, методы увеличения данных, регуляризацию и примеры их использования.
Основы сверточных нейронных сетей (CNN)
Сверточный слой (Convolutional Layer)
Сверточный слой — основной элемент CNN, который выполняет свертку между входными данными (например, изображением) и фильтрами (ядрами свертки). Фильтр — это небольшая матрица весов, которая скользит по изображению и извлекает локальные признаки (например, границы, углы).
Основные параметры сверточного слоя:
- Размер ядра (kernel size): Размер матрицы фильтра, обычно 3×3 или 5×5.
- Шаг (stride): Количество пикселей, на которое перемещается фильтр при каждом шаге. Чем больше шаг, тем меньше выходной размер изображения.
- Padding: Добавление рамки из нулей вокруг изображения для сохранения его размера при свертке.
Пример работы свертки:
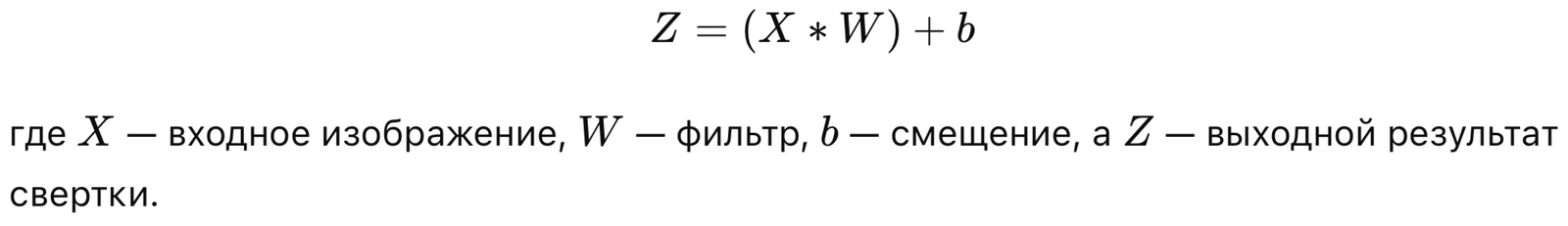
Функция активации (Activation Function)
После применения свертки используется функция активации для добавления нелинейности. В CNN чаще всего используется ReLU (Rectified Linear Unit), которая преобразует все отрицательные значения в ноль, сохраняя только положительные.
Формула ReLU:
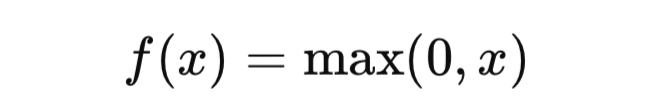
Пуллинговый слой (Pooling Layer)
Пуллинг (Pooling) используется для уменьшения пространственных размеров изображения, что снижает количество параметров и вычислительную сложность. Наиболее распространённый тип — Max Pooling, который выбирает максимальное значение из области (например, 2×2).
Пример:

Полносвязные слои (Fully Connected Layers)
Полносвязные слои располагаются в конце сети и используются для принятия окончательного решения (например, классификации). Каждый нейрон на этом этапе связан со всеми нейронами предыдущего слоя, что позволяет объединять признаки, извлечённые сверточными слоями.
Пример архитектуры CNN с использованием Keras:
from tensorflow.keras.models import Sequential from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense # Создание модели CNN model = Sequential() # Первый сверточный слой model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(64, 64, 3))) # Max Pooling model.add(MaxPooling2D(pool_size=(2, 2))) # Второй сверточный слой model.add(Conv2D(64, (3, 3), activation='relu')) # Max Pooling model.add(MaxPooling2D(pool_size=(2, 2))) # Преобразование в плоский вектор model.add(Flatten()) # Полносвязный слой model.add(Dense(128, activation='relu')) # Выходной слой model.add(Dense(10, activation='softmax')) # Классификация на 10 классов # Компиляция модели model.compile(optimizer='adam', loss='categorical_crossentropy', metrics=['accuracy'])
Продвинутые архитектуры CNN
ResNet (Residual Networks)
ResNet — это архитектура, разработанная для решения проблемы исчезающего градиента в очень глубоких сетях. Основная идея — использование остаточных блоков (residual blocks), в которых прямой сигнал от входа добавляется к выходу слоя через «shortcut connection». Это позволяет глубже обучать сеть без потери точности.
Пример структуры остаточного блока:
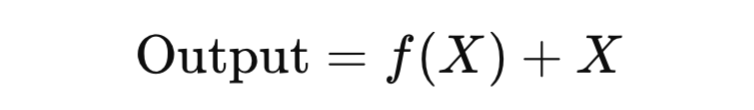
VGG (Visual Geometry Group)
VGG — это архитектура, использующая несколько небольших сверточных фильтров (обычно 3×3). Она доказала свою эффективность в задачах классификации и распознавания объектов. В VGG важную роль играет глубина сети, что позволяет извлекать более сложные признаки.
Inception (GoogLeNet)
Inception — это архитектура, использующая параллельные свертки разного размера (например, 1×1, 3×3, 5×5) для захвата признаков на различных пространственных масштабах. Это делает модель более эффективной и позволяет захватывать как мелкие, так и крупные объекты.
MobileNet
MobileNet — это архитектура, оптимизированная для мобильных устройств. Она использует глубинные разделяемые свертки (depthwise separable convolutions), что позволяет значительно сократить количество параметров и вычислительных ресурсов без значительной потери точности.
Визуализация работы CNN
Для лучшего понимания того, как CNN «видят» изображение, можно использовать визуализацию фильтров и карт признаков. Визуализация показывает, как различные слои сети выделяют признаки — от простых краев и углов в первых слоях до более сложных объектов в последних.
Пример визуализации активаций с использованием Keras:
from tensorflow.keras.models import Model import matplotlib.pyplot as plt # Создание модели, выводящей активации слоев layer_outputs = [layer.output for layer in model.layers[:4]] # Первые четыре слоя activation_model = Model(inputs=model.input, outputs=layer_outputs) # Визуализация активаций для тестового изображения activations = activation_model.predict(test_image) # Визуализация активации первого сверточного слоя first_layer_activation = activations[0] plt.matshow(first_layer_activation[0, :, :, 0], cmap='viridis') # Отображение первой карты признаков plt.show()
Увеличение данных (Data Augmentation)
Увеличение данных — это техника, позволяющая искусственно увеличивать размер обучающего набора данных за счёт различных преобразований изображений. Это помогает улучшить обобщающую способность модели и снизить риск переобучения.
Примеры техник увеличения данных:
- Повороты и сдвиги: Изменение ориентации изображений.
- Отражение: Горизонтальное и вертикальное зеркальное отражение.
- Изменение яркости и контраста: Изменение освещенности и контрастности.
- Растяжения и обрезка: Увеличение или уменьшение объектов на изображении.
Пример использования увеличения данных в Keras:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# Создание генератора данных
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)
# Пример использования с обучающими данными
datagen.fit(X_train)
model.fit(datagen.flow(X_train, y_train, batch_size=32), epochs=50)
Регуляризация для CNN
Регуляризация помогает предотвратить переобучение, улучшая обобщающую способность модели. В CNN часто используются следующие методы регуляризации:
- Dropout: Случайное отключение нейронов во время обучения для предотвращения избыточной зависимости от отдельных нейронов. Это помогает сети стать более устойчивой к шуму в данных.
- L2-регуляризация: Добавляет штраф за большие значения весов, что помогает избежать переобучения.
#Пример использования Dropout в Keras: from tensorflow.keras.layers import Dropout model.add(Dense(128, activation='relu')) model.add(Dropout(0.5)) # 50% нейронов отключаются на каждом шаге #Пример использования L2-регуляризации: from tensorflow.keras.regularizers import l2 model.add(Dense(128, activation='relu', kernel_regularizer=l2(0.01)))
Применение CNN
Сверточные нейронные сети используются для решения различных задач компьютерного зрения:
- Классификация изображений: CNN широко применяются для задач классификации изображений, таких как распознавание лиц, классификация объектов и сцен.
- Распознавание объектов: Модели, такие как YOLO и Faster R-CNN, позволяют обнаруживать объекты на изображениях, определяя их местоположение и класс.
- Сегментация изображений: Архитектуры, такие как U-Net и Mask R-CNN, применяются для сегментации изображений, что особенно полезно в медицинской диагностике.
- Анализ видеопотоков: CNN используются для анализа и отслеживания объектов в видеопотоках в реальном времени.
Заключение
Сверточные нейронные сети (CNN) — это ключевая архитектура для задач компьютерного зрения. Они позволяют эффективно извлекать признаки из изображений, решать задачи классификации, распознавания объектов и сегментации. Современные архитектуры, такие как ResNet и Inception, продолжают развивать возможности CNN, делая их более мощными и точными. Визуализация работы сетей, увеличение данных и методы регуляризации помогают улучшить их обобщающие способности и повысить производительность в реальных приложениях.
Рекомендации для самостоятельного изучения:
- Книга «Deep Learning» от Ian Goodfellow.
- Онлайн-курсы по компьютерному зрению на Coursera.
- Практические задачи на Kaggle (включая использование CNN для классификации и распознавания изображений).
Добавить комментарий