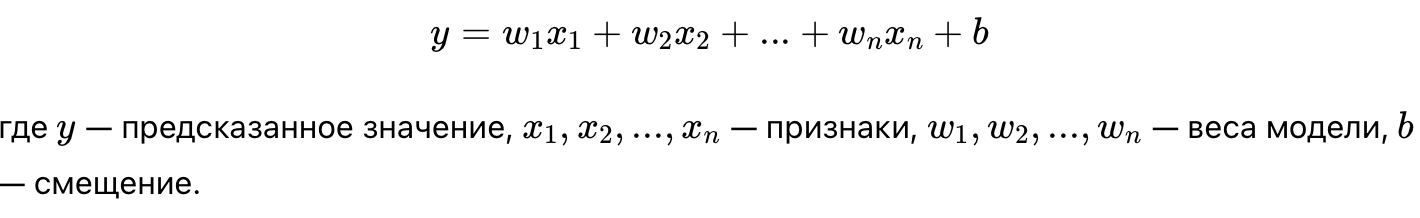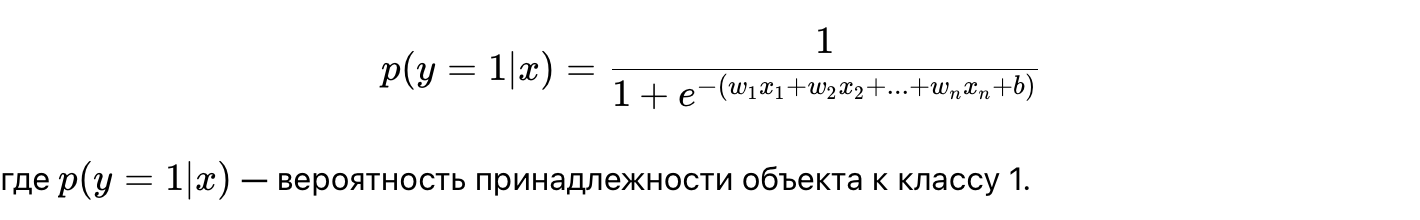Я объясню шаблоны программирования в контексте PHP. Мы разберем, что это такое, зачем они нужны и как их использовать на практике. Я объясню все простым языком, чтобы сделать шаблоны более доступными и понятными.
Введение
Шаблоны программирования — это готовые шаблоны для решения распространенных задач программирования. Если вы когда-либо обнаруживали, что пишете одно и то же решение несколько раз, значит, вы интуитивно уже использовали шаблон.
Почему важны шаблоны? Они позволяют писать код, который легко поддерживать, расширять и рефакторить. Благодаря шаблонам можно избежать распространенных ошибок и сократить количество «изобретений велосипеда». В PHP, как и в других языках, шаблоны широко используются в фреймворках и библиотеках.
Классификация шаблонов
Все паттерны можно условно разделить на три группы:
- Творческие — помогают управлять процессом создания объектов.
- Структурные — решают задачи, связанные с тем, как объекты взаимодействуют друг с другом.
- Поведенческие — фокусируются на коммуникации и потоке данных между объектами.
Творческие паттерны
Творческие паттерны — это все о том, как создаются объекты. Вы можете подумать: «Насколько сложно создать объект?» Но иногда важно не просто создать объект, а сделать это правильно, особенно если объект сложный или зависит от контекста.
- Factory Method : помогает создавать объекты без указания точного класса создаваемого объекта. Представьте, что у вас есть несколько классов (например, MySQL и PostgreSQL). Вместо того, чтобы вручную создавать экземпляры этих классов, вы можете делегировать создание фабрике.
Пример:
interface Database {
public function connect();
}
class MySQL implements Database {
public function connect() {
// Connect to MySQL
}
}
class DatabaseFactory {
public static function create($type): Database {
if ($type === 'mysql') {
return new MySQL();
}
// Other databases
}
}
$db = DatabaseFactory::create('mysql');
$db->connect();
- Singleton : этот шаблон гарантирует, что у класса есть только один экземпляр. Он полезен, когда вам нужна одна точка доступа, например, подключение к базе данных.
Пример:
class Singleton {
private static $instance;
private function __construct() {}
public static function getInstance(): Singleton {
if (self::$instance === null) {
self::$instance = new Singleton();
}
return self::$instance;
}
}
$singleton = Singleton::getInstance();
Структурные паттерны
Структурные шаблоны — это организация объектов и классов. Они помогают создавать гибкие и расширяемые архитектуры.
- Адаптер : этот шаблон используется, когда вам нужно «соединить» два несовместимых интерфейса. Например, если у вас есть класс, который ожидает один интерфейс, но у вас есть другой класс с другим интерфейсом, вы можете использовать адаптер, чтобы связать их.
Пример:
class OldLogger {
public function log($message) {
echo $message;
}
}
class NewLoggerAdapter {
private $oldLogger;
public function __construct(OldLogger $oldLogger) {
$this->oldLogger = $oldLogger;
}
public function logMessage($message) {
$this->oldLogger->log($message);
}
}
$oldLogger = new OldLogger();
$logger = new NewLoggerAdapter($oldLogger);
$logger->logMessage("This message through the adapter");
- Декоратор : этот шаблон позволяет добавлять функциональность объекту, не изменяя его структуру. Он полезен, когда нужно расширить возможности объекта, не изменяя его код напрямую.
Пример:
interface Notifier {
public function send($message);
}
class EmailNotifier implements Notifier {
public function send($message) {
echo "Sending email: $message";
}
}
class SMSNotifierDecorator implements Notifier {
private $notifier;
public function __construct(Notifier $notifier) {
$this->notifier = $notifier;
}
public function send($message) {
$this->notifier->send($message);
echo " Sending SMS: $message";
}
}
$notifier = new SMSNotifierDecorator(new EmailNotifier());
$notifier->send("Hello");
Поведенческие паттерны
Поведенческие модели фокусируются на том, как объекты взаимодействуют друг с другом. Эти модели помогают организовать эффективную коммуникацию и управление данными в системе.
- Стратегия : этот шаблон позволяет определить семейство алгоритмов, инкапсулировать их и сделать их взаимозаменяемыми. В PHP это полезно для создания гибких и расширяемых решений, где поведение объекта может быть изменено на лету.
Пример:
interface PaymentStrategy {
public function pay($amount);
}
class PayPalPayment implements PaymentStrategy {
public function pay($amount) {
echo "Paying via PayPal: $amount";
}
}
class CreditCardPayment implements PaymentStrategy {
public function pay($amount) {
echo "Paying via Credit Card: $amount";
}
}
class Order {
private $paymentMethod;
public function __construct(PaymentStrategy $paymentMethod) {
$this->paymentMethod = $paymentMethod;
}
public function process($amount) {
$this->paymentMethod->pay($amount);
}
}
$order = new Order(new PayPalPayment());
$order->process(100);
- Наблюдатель : этот шаблон помогает одному объекту контролировать состояние другого. Например, если у вас есть объект, контролируемый несколькими другими объектами (наблюдателями), они автоматически получают обновления при изменении объекта.
Пример:
class Subject {
private $observers = [];
public function attach($observer) {
$this->observers[] = $observer;
}
public function notify() {
foreach ($this->observers as $observer) {
$observer->update();
}
}
}
class Observer {
public function update() {
echo "Object was updated!";
}
}
$subject = new Subject();
$observer = new Observer();
$subject->attach($observer);
$subject->notify();
Реальные примеры использования шаблонов
Шаблоны повсюду в PHP. Например, фреймворк Laravel использует шаблон Singleton для таких сервисов, как доступ к базе данных или конфигурация. Фабрики и стратегии также часто используются для обработки различных типов запросов.
Когда использовать шаблоны
Шаблоны программирования — мощный инструмент, помогающий создавать более качественный и понятный код. Сначала они могут показаться сложными, но со временем, по мере того как вы понимаете их суть, они становятся неотъемлемой частью вашего рабочего процесса.
Используйте шаблоны, когда это действительно оправдано. Нет нужды усложнять код, если проблему можно решить проще. Шаблоны особенно полезны в крупных проектах, где гибкость и удобство обслуживания имеют решающее значение.