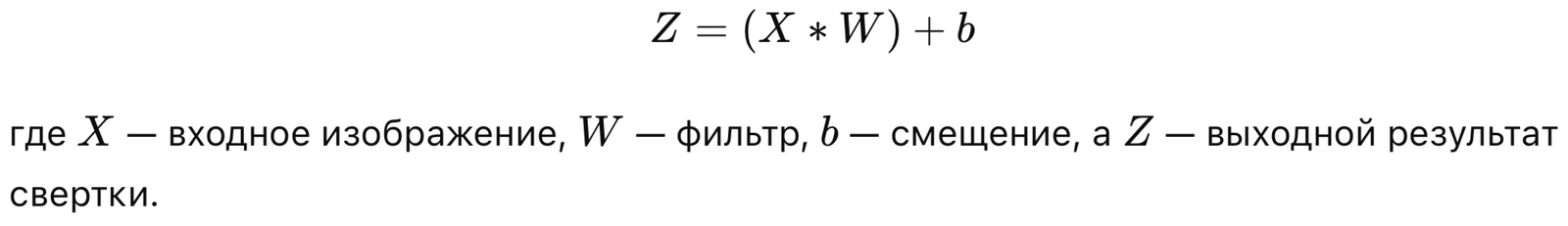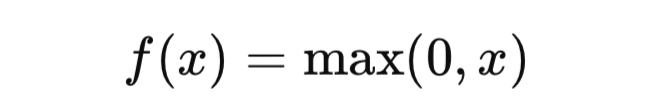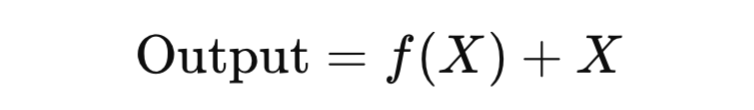Добро пожаловать в свежий выпуск нашего AI дайджеста! Технологии искусственного интеллекта продолжают удивлять и развиваться, открывая все больше возможностей для бизнеса, науки и повседневной жизни. В этом выпуске мы рассмотрим самые значимые события недели, от новинок в AI инфраструктуре до нестандартных подходов к применению AI в криптовалютном секторе. Наслаждайтесь чтением!
Alibaba сокращает мета-вселенское подразделение
Alibaba приняла решение сократить значительное количество сотрудников в своем подразделении по разработке мета-вселенных. Снижение активности в этой сфере указывает на пересмотр стратегического подхода компании и адаптацию к быстро меняющимся рынкам. Возможно, гигант планирует сосредоточиться на более прибыльных направлениях, таких как AI и облачные технологии.
Samsung использует блокчейн для безопасности AI-устройств
Samsung интегрирует блокчейн для обеспечения безопасности своих AI-устройств умного дома. С помощью этой технологии компания намерена защитить персональные данные пользователей от киберугроз. Этот шаг может стать значимым прорывом в области безопасности, подтверждая важность блокчейн-технологий для повышения доверия к устройствам с искусственным интеллектом.
AI-агенты и криптовалюты: от гипотез к реальности
Концепция AI-агентов становится все более реальной в криптопространстве. Речь идет о специализированных алгоритмах, способных принимать решения на основе данных с рынка и автоматизировать торговые операции. Они обещают улучшить результаты торговли и обеспечить более точные прогнозы, хотя и вызывают вопросы относительно рисков и безопасности.
Рост затрат на майнинг и AI как спасение
Затраты на майнинг биткоина продолжают расти, и компании обращаются к AI для повышения эффективности. AI-технологии могут помочь оптимизировать процессы добычи, сократив расходы на энергопотребление и снизив воздействие на окружающую среду. Это новый виток в развитии криптоиндустрии, который может сыграть решающую роль в борьбе за выживание.
Meta открывает доступ к LLaMA для нужд национальной безопасности США
Компания Meta предоставила Министерству обороны США доступ к своей AI-модели LLaMA. Этот шаг направлен на обеспечение безопасности и улучшение аналитических возможностей национальной обороны. Модель позволит быстрее анализировать данные и принимать решения в реальном времени, что подчеркивает важность AI в обеспечении безопасности.
OpenAI рассматривает создание дочерней коммерческой компании
Создатели ChatGPT, OpenAI, находятся на стадии переговоров о запуске коммерческой дочерней компании. Целью является привлечение дополнительных инвестиций и ускорение разработки продуктов. Новая структура позволит компании легче адаптироваться к потребностям рынка, сохраняя при этом основное внимание на инновациях и этике.
OpenAI запускает аппаратное подразделение
OpenAI объявила о создании подразделения для разработки потребительских устройств. Ведущий специалист из Meta по разработке AR возглавит команду. Это решение указывает на намерение OpenAI выйти на рынок пользовательской электроники, что может значительно расширить доступ к их технологиям.
Неудачные сделки технологических гигантов и влияние на майнинг
Ряд энергетических сделок крупных технологических компаний потерпел неудачу, что может сказаться на майнинге. Теперь майнеры вынуждены искать альтернативные источники энергии, в том числе AI-технологии для повышения эффективности использования ресурсов. Это подчеркивает важность устойчивости в индустрии и необходимость адаптации к энергетическим вызовам.
Децентрализованная AI-платформа запускает самосовершенствующийся бот в Minecraft
SingularityNET запускает бота, способного к саморазвитию, в рамках игры Minecraft. Платформа предоставляет пользователям возможность взаимодействовать с AI в интерактивной среде. Этот проект демонстрирует, как децентрализованные технологии могут способствовать созданию инновационных AI-решений.
Anthropic и Palantir создают AI-инструменты для обороны США
Компании Anthropic и Palantir представили AI-инструменты для Министерства обороны США. Эти решения предназначены для анализа больших данных и поддержки стратегических решений. Подобные разработки усиливают позиции США в области национальной безопасности и подчеркивают роль искусственного интеллекта в обороне.
OpenAI избегает иска по поводу авторских прав
OpenAI удалось избежать иска, связанного с использованием новостных материалов для обучения AI. Этот случай поднимает вопрос о правовых аспектах использования данных для обучения алгоритмов и может стать прецедентом для AI-индустрии.
Withanage Foundation делает ставку на AI-исследования в Африке
Фонд Withanage Foundation запускает программу поддержки AI-исследований в Африке. Эта инициатива направлена на развитие местных специалистов и создание новых решений, ориентированных на потребности африканского региона. Проект обещает ускорить развитие технологий на континенте.
Near создаст крупнейшую AI-модель с открытым исходным кодом
Проект Near анонсировал планы по созданию крупнейшей в мире AI-модели с открытым исходным кодом объемом в 1,4 триллиона параметров. Это может изменить рынок, предлагая мощные аналитические возможности для исследователей и разработчиков. Доступ к такой модели значительно упростит внедрение AI-технологий.
Каждая из этих новостей демонстрирует широкие возможности и вызовы, с которыми сталкивается индустрия AI. Искусственный интеллект продолжает завоевывать новые горизонты, изменяя мир и наши представления о будущем.