

Машинное обучение (ML) — это область искусственного интеллекта, которая занимается разработкой алгоритмов для создания моделей, способных обучаться на данных и делать прогнозы без явного программирования. Существуют три основных вида машинного обучения, которые различаются по характеру данных и типу задач: обучение с учителем, обучение без учителя и обучение с подкреплением. В этом материале мы подробно рассмотрим каждый из этих видов, включая их особенности, примеры, алгоритмы и области применения.
1. Обучение с учителем (Supervised Learning)
Обучение с учителем — это тип машинного обучения, при котором модель обучается на размеченных данных, где каждый входной пример сопровождается правильным ответом (меткой). Цель заключается в том, чтобы модель научилась предсказывать правильные ответы на новых данных, используя закономерности, выявленные на обучающих данных.
- Входные данные: Набор пар «вход — выход», где входные данные представляют собой признаки, а выходные — это метки классов (в классификации) или числовые значения (в регрессии).
- Цель: Обучить модель предсказывать метку или значение для новых примеров.
Типы задач
- Классификация: Когда результатом работы модели является предсказание класса для каждого примера. (Пример: Классификация изображений, где модель предсказывает, что на изображении (например, «кошка» или «собака»).)
- Регрессия: Когда модель предсказывает непрерывное числовое значение. (Пример: Прогнозирование цен на недвижимость на основе характеристик объектов.)
Алгоритмы обучения с учителем
Некоторые популярные алгоритмы:
- Линейная регрессия: Алгоритм регрессии, который строит линейную зависимость между входными данными и результатом. Например, для прогнозирования цен на основе квадратных метров.
- Логистическая регрессия: Алгоритм классификации, который оценивает вероятность того, что объект принадлежит к одному из двух классов.
- Дерево решений: Алгоритм, который строит древовидную структуру для принятия решений, разделяя данные на основе их признаков.
- Метод опорных векторов (SVM): Алгоритм классификации, который строит гиперплоскость для разделения данных на классы с максимальной границей между ними.
- Нейронные сети: Многослойные структуры, которые обучаются на больших объемах данных и могут решать как задачи классификации, так и регрессии.
Пример задачи с учителем
Рассмотрим пример задачи классификации с использованием логистической регрессии:
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
# Загрузка данных (цифры)
digits = load_digits()
X = digits.data
y = digits.target
# Разделение данных на обучающую и тестовую выборки
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Создание и обучение модели логистической регрессии
model = LogisticRegression(max_iter=10000)
model.fit(X_train, y_train)
# Оценка точности на тестовой выборке
y_pred = model.predict(X_test)
print(f"Точность модели: {accuracy_score(y_test, y_pred):.4f}")
Преимущества и ограничения обучения с учителем
Преимущества:
- Высокая точность, если имеется достаточное количество размеченных данных.
- Хорошо подходит для предсказательных задач, таких как классификация и регрессия.
Ограничения:
- Требует большого количества размеченных данных, что может быть дорого и трудоемко.
- Плохая переносимость на задачи с изменяющимися условиями (например, если данные со временем меняются).
2. Обучение без учителя (Unsupervised Learning)
Обучение без учителя — это метод машинного обучения, при котором модель обучается на данных без меток классов. Цель состоит в том, чтобы выявить скрытые закономерности или структуру в данных. Модель анализирует входные данные и пытается найти зависимости и паттерны без какой-либо дополнительной информации о правильных ответах.
- Входные данные: Только входные данные (без меток классов).
- Цель: Найти структуру или группировки в данных.
Типы задач
- Кластеризация: Задача разбиения данных на группы (кластеры), где объекты в одном кластере схожи по характеристикам. (Пример: Разделение клиентов интернет-магазина на группы на основе их покупательского поведения.)
- Снижение размерности: Уменьшение числа признаков для более эффективного анализа данных. (Пример: PCA (анализ главных компонент) для визуализации многомерных данных в 2D или 3D пространстве.)
Алгоритмы обучения без учителя
- K-means: Алгоритм кластеризации, который разбивает данные на K кластеров на основе близости объектов друг к другу.
- DBSCAN: Алгоритм плотностной кластеризации, который находит кластеры произвольной формы на основе плотности данных.
- PCA (анализ главных компонент): Метод уменьшения размерности данных, который проецирует их в новое пространство с меньшим числом признаков.
Пример задачи без учителя
Пример с кластеризацией методом K-средних:
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
# Загрузка данных
X, _ = load_digits(return_X_y=True)
# Кластеризация методом KMeans
kmeans = KMeans(n_clusters=10, random_state=42)
clusters = kmeans.fit_predict(X)
# Визуализация данных
plt.scatter(X[:, 0], X[:, 1], c=clusters, cmap='viridis')
plt.title('Кластеризация методом KMeans')
plt.show()
Преимущества и ограничения обучения без учителя
Преимущества:
- Не требует размеченных данных, что делает его более гибким для работы с необработанными данными.
- Помогает находить скрытые закономерности и структуры, которые могут быть неочевидны.
Ограничения:
- Интерпретация результатов может быть сложной, так как модель не предоставляет явных меток.
- Трудно оценить качество обучения, поскольку нет правильных ответов.
3. Обучение с подкреплением (Reinforcement Learning)
Обучение с подкреплением — это тип машинного обучения, при котором агент обучается через взаимодействие с окружающей средой. Агент совершает действия, получает обратную связь в виде наград или штрафов и корректирует свои действия для максимизации общей награды. Этот подход особенно полезен для задач, где агент должен научиться принимать решения в динамической и меняющейся среде.
- Агент: Система, которая принимает решения.
- Среда: Окружающая среда, с которой взаимодействует агент.
- Награда: Обратная связь, которую получает агент за свои действия.
- Цель: Максимизировать накопленную награду за долгосрочный период.
Процесс обучения с подкреплением
- Агент выполняет действие в среде.
- Среда меняет своё состояние и отправляет агенту награду (или штраф).
- Агент корректирует свою стратегию на основе полученной награды, чтобы улучшить свои действия в будущем.
Пример использования обучения с подкреплением
Алгоритмы обучения с подкреплением применяются в робототехнике, управлении ресурсами, стратегических играх (например, AlphaGo) и других задачах, где агент должен принимать последовательные решения в изменяющейся среде.
Алгоритмы обучения с подкреплением
- Q-Learning: Агент строит таблицу QQ-значений, где каждая ячейка соответствует состоянию и действию. Агент выбирает действия, максимизирующие ожидаемую награду.
- Deep Q-Networks (DQN): Усовершенствованный метод Q-Learning с использованием нейронных сетей для аппроксимации функции ценности.
Пример Q-Learning:
import numpy as np
import gym
# Создание среды
env = gym.make('FrozenLake-v1')
# Параметры Q-learning
alpha = 0.1 # скорость обучения
gamma = 0.99 # фактор дисконтирования
epsilon = 0.1 # вероятность выбора случайного действия
q_table = np.zeros([env.observation_space.n, env.action_space.n])
# Обучение
for episode in range(1000):
state = env.reset()
done = False
while not done:
if np.random.uniform(0, 1) < epsilon:
action = env.action_space.sample() # случайное действие
else:
action = np.argmax(q_table[state]) # действие, максимизирующее награду
next_state, reward, done, _ = env.step(action)
q_table[state, action] = q_table[state, action] + alpha * (reward + gamma * np.max(q_table[next_state]) - q_table[state, action])
state = next_state
# Оценка обученной стратегии
print(f"Q-таблица:\n{q_table}")
Преимущества и ограничения обучения с подкреплением
Преимущества:
- Подходит для задач, где нужно принимать последовательные решения в условиях неопределенности.
- Используется в играх, робототехнике и управлении системами.
Ограничения:
- Требует значительных вычислительных ресурсов и времени для обучения.
- Нестабильность и сложность настройки параметров (например, награды и штрафы).
Сравнение видов машинного обучения
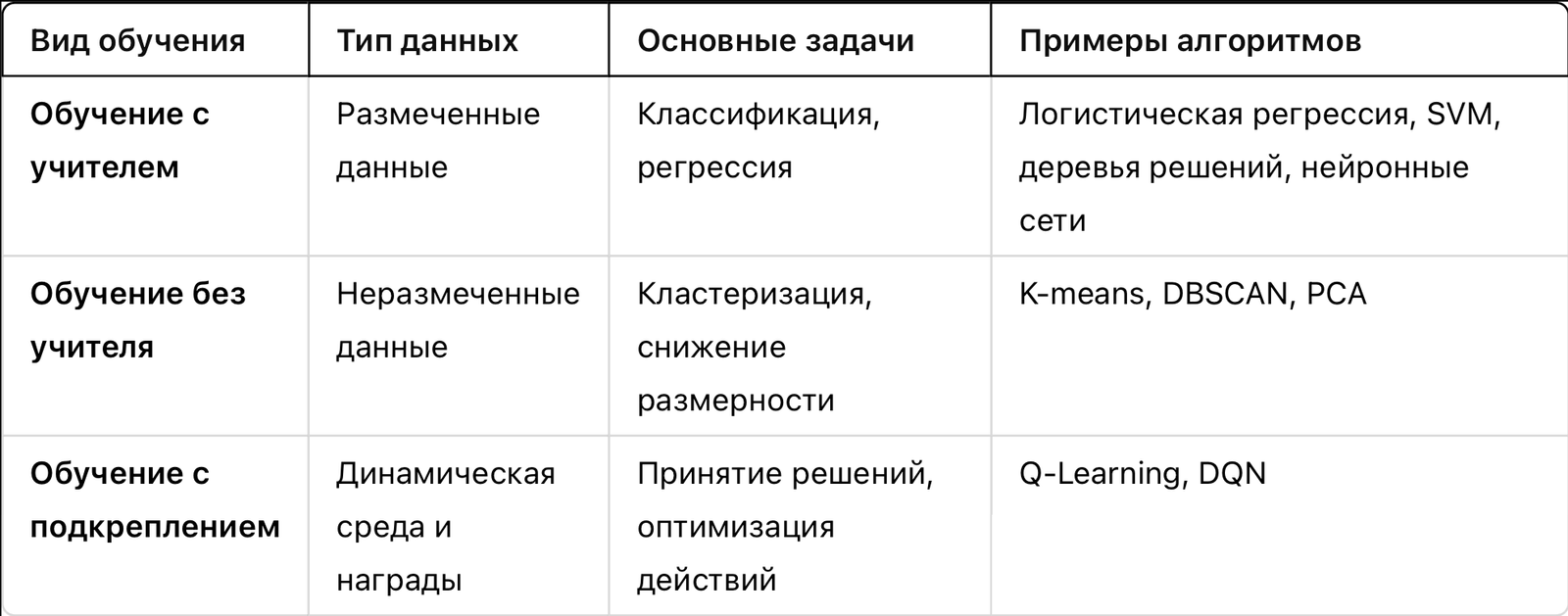
Заключение
Машинное обучение делится на три основные категории: обучение с учителем, обучение без учителя и обучение с подкреплением. Каждый тип имеет свои особенности и применяется в зависимости от типа задачи и доступных данных. Понимание этих методов помогает выбирать подходящие модели для различных проблем и добиваться лучших результатов.
Рекомендации для самостоятельного изучения:
- Книга «Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow» от Aurélien Géron.
- Онлайн-курсы по машинному обучению на Coursera и edX.
- Лекции по машинному обучению от MIT OpenCourseWare.
Добавить комментарий