
Обучение с подкреплением (Reinforcement Learning, RL) — это метод машинного обучения, при котором агент учится взаимодействовать с средой, чтобы максимизировать долгосрочное вознаграждение. В отличие от обучения с учителем, где модель обучается на размеченных данных, или обучения без учителя, где анализируются закономерности, RL основан на механизме проб и ошибок.
Этот метод применяется в сложных динамических задачах, таких как управление роботами, игры, финансовые системы, управление ресурсами.
Основные концепции RL
- Агент (Agent) – система, которая принимает решения.
- Среда (Environment) – окружение, с которым взаимодействует агент.
- Состояние (State) – информация о текущем состоянии среды.
- Действие (Action) – выбор агента, влияющий на среду.
- Политика (Policy, π(s)) – стратегия агента, определяющая, какое действие выполнять в каждом состоянии.
- Награда (Reward) – обратная связь от среды за действие агента.
- Функция ценности (Value Function) – оценка полезности нахождения в данном состоянии.
- Функция действия-ценности (Q-Function) – оценка полезности выбора конкретного действия в состоянии.
- Дисконт-фактор (Discount Factor) – коэффициент, определяющий важность будущих наград.
Цель RL — найти оптимальную стратегию, которая максимизирует суммарное вознаграждение:
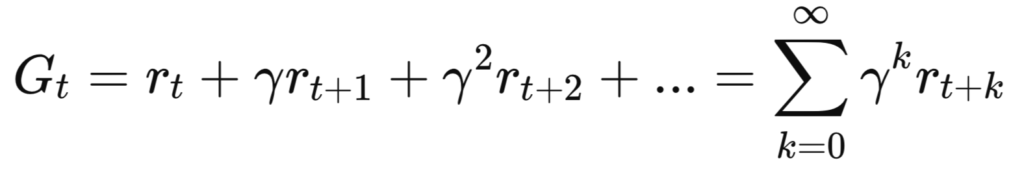
где дисконт-фактор определяет, насколько важны будущие награды.
Уравнение Беллмана
Функция ценности V(s) описывает ожидаемое вознаграждение, если агент действует согласно политике π:

Аналогично, Q-функция:
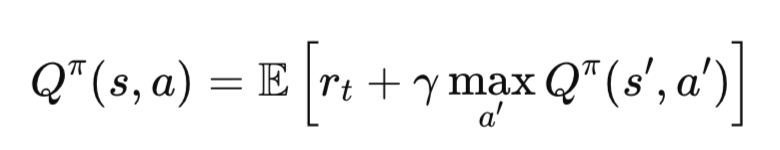
Эти уравнения используются в алгоритмах RL для обновления знаний агента.
Методы обучения с подкреплением
1. Методы, основанные на ценности (Value-Based Methods)
Агент учится оценивать ценность состояний или действий, используя Q-функцию.
Примеры:
- Q-Learning – обучает Q-функцию с обновлением по уравнению Беллмана.
- Deep Q-Network (DQN) – использует нейросети вместо Q-таблицы.
2. Методы, основанные на политике (Policy-Based Methods)
Агент обучается не через Q-функцию, а напрямую выбирает действия.
Примеры:
- REINFORCE – алгоритм градиента политики.
- Proximal Policy Optimization (PPO) – улучшенная версия градиентных методов.
3. Гибридные методы (Actor-Critic Methods)
Комбинируют оценку политики и ценности, улучшая стабильность обучения.
Примеры:
- Advantage Actor-Critic (A2C)
- Deep Deterministic Policy Gradient (DDPG) – применяется в средах с непрерывными действиями.
Q-Learning: пример реализации
import numpy as np
import gym
# Создание среды OpenAI Gym
env = gym.make("FrozenLake-v1", is_slippery=False)
# Инициализация Q-таблицы
q_table = np.zeros([env.observation_space.n, env.action_space.n])
alpha = 0.1 # Скорость обучения
gamma = 0.99 # Дисконт-фактор
epsilon = 1.0 # Степень исследования (exploration)
epsilon_decay = 0.995
# Обучение агента
num_episodes = 1000
for episode in range(num_episodes):
state = env.reset()[0]
done = False
while not done:
# Выбор действия
if np.random.rand() < epsilon:
action = env.action_space.sample()
else:
action = np.argmax(q_table[state, :])
# Выполнение действия
new_state, reward, done, _, _ = env.step(action)
# Обновление Q-таблицы
q_table[state, action] += alpha * (reward + gamma * np.max(q_table[new_state, :]) - q_table[state, action])
state = new_state
# Уменьшение epsilon
epsilon *= epsilon_decay
print("Обучение завершено!")
Deep Q-Network (DQN)
Ключевые особенности DQN:
- Использует глубокие нейросети вместо Q-таблицы.
- Применяет Replay Buffer для хранения опыта и выборки случайных данных.
- Включает Target Network для стабилизации обучения.
Пример создания DQN-модели:
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
# Создание модели
def build_dqn(state_size, action_size):
model = Sequential([
Dense(24, activation='relu', input_shape=(state_size,)),
Dense(24, activation='relu'),
Dense(action_size, activation='linear')
])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.001), loss='mse')
return model
Применение RL
- Игры: AlphaGo, AlphaZero, OpenAI Five (Dota 2).
- Робототехника: Управление дронами, манипуляция объектами.
- Финансы: Автоматическая торговля, управление портфелями.
- Оптимизация маршрутов: Управление трафиком, дроны для доставки.
- Управление ресурсами: Энергосбережение, адаптивные стратегии.
Ограничения RL
- Высокая вычислительная сложность – обучение требует большого количества проб и ошибок.
- Проблема разреженных наград – некоторые задачи дают вознаграждение редко, что затрудняет обучение.
- Проблема баланса исследования и эксплуатации – агент должен балансировать между изучением новых действий и использованием наилучших известных стратегий.
Обучение с подкреплением – мощный инструмент для решения задач, требующих взаимодействия с динамической средой. Методы RL позволяют моделировать поведение агентов, способных адаптироваться к изменяющимся условиям. Современные алгоритмы, такие как DQN, PPO и A2C, делают RL применимым в реальных сценариях.
Рекомендации для самостоятельного изучения:
- Практикуйтесь с OpenAI Gym.
- Изучите Deep Q-Network (DQN) и Policy Gradient Methods.
- Попробуйте обучить агента в игре Atari или симуляции управления дроном.
Добавить комментарий